Introduction
Historique
Cartes perforées
1725 : orgue de Barbarie (figure )

1801 : métier à tisser Jacquard (figure )

1908 : Charles Babbage, ordinateurs (figure )

Imprimantes / Écrans / claviers
Ordinateur “personnel” : 1960
1964 : IBM 2260 (figure )

Codage des caractères
- Police de caractères : dessin des caractères (glyphes)
- Codage : correspondance entre caractères et nombres
Exemple : lettre “A” => numéro 65
ASCII et successeurs
ASCII
American Standard Code for Information Interchange
- fiabilité des transmissions : erreurs de transmission
- 1963 : 7 bits, 128 caractères
- 1 bit de parité (optionnel)
Bit de parité
- 1 bit de parité : vaut 1 ou 0 de sorte que le nombre de 1 dans le mot soit pair (parité paire).
Exemple :
- 1 001 0101 valide
- 1 001 0100 invalide
ASCII : 7 bits
- 7 bits : 128 caractères
- 33 caractères de contrôle (non imprimables)
- 95 caractères imprimables
- 26 lettres majuscules
- 26 lettres minuscules
- 10 chiffres
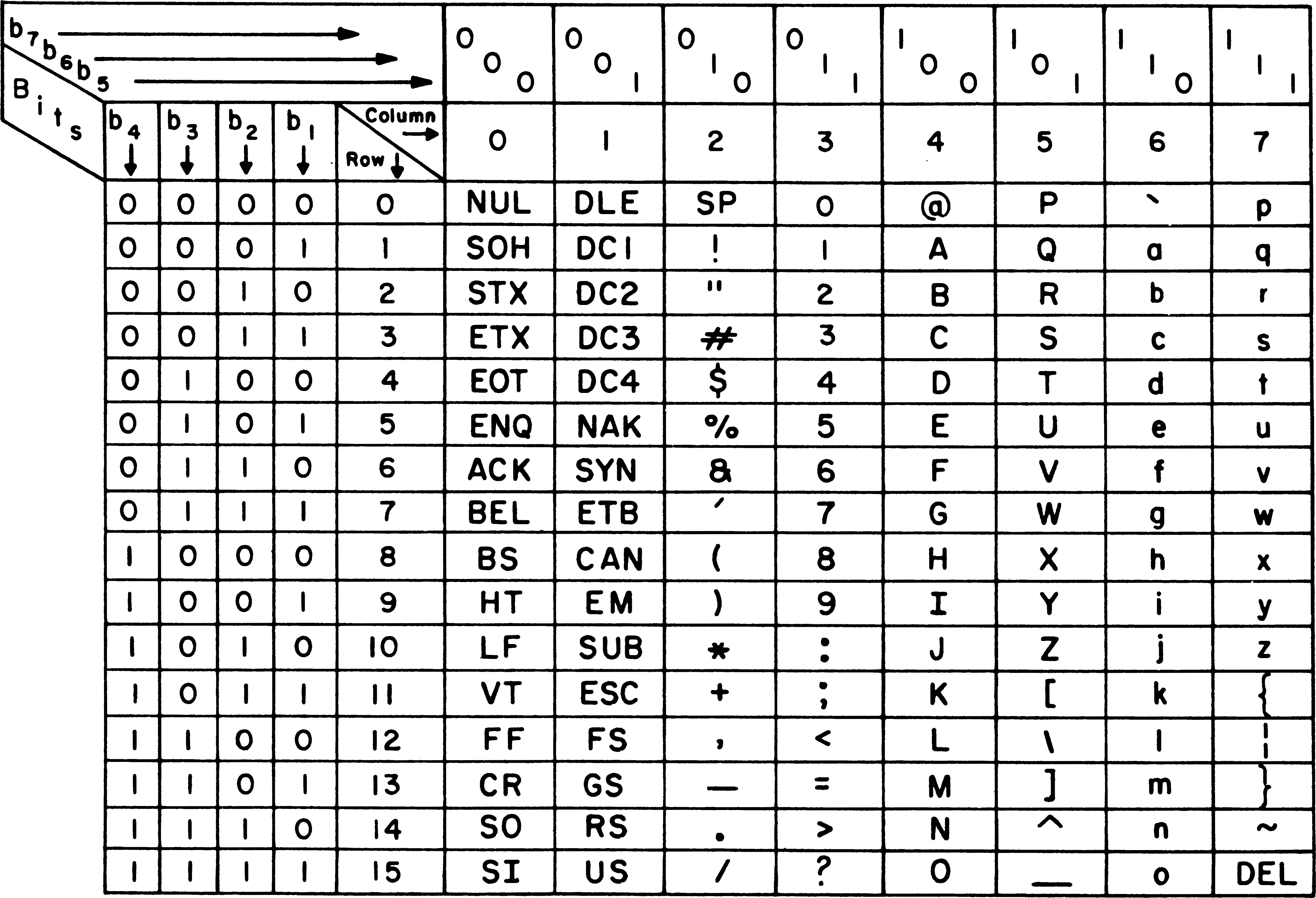
Table ASCII
127 caractères de la table ASCII : figure
Affichage en python
Fonction chr : caractère correspondant à un code
# Basique
for c in range(128):
print(chr(c))
# Plus joli
for c in range(32,128):
print(f"{c:03d}={chr(c)}", end=" ")
if c % 8 == 7:
print()ISO-8859
ISO-8859
- 1987 : 8 bits, 256 caractères
- pas assez pour les langues européennes
- encore moins pour les langues asiatiques
Principe
- 8 bits : 256 caractères
- chaque langue a sa propre table
- ISO-8859-1 : latin-1 (français, allemand, espagnol, italien, etc.)
- ISO-8859-2 : latin-2 (polonais, tchèque, slovaque, etc.)
- ISO-8859-5 : cyrillique
- ISO-8859-7 : grec
- ISO-8859-8 : hébreu
- ISO-8859-9 : turc
- ISO-8859-15 : latin-1 + €
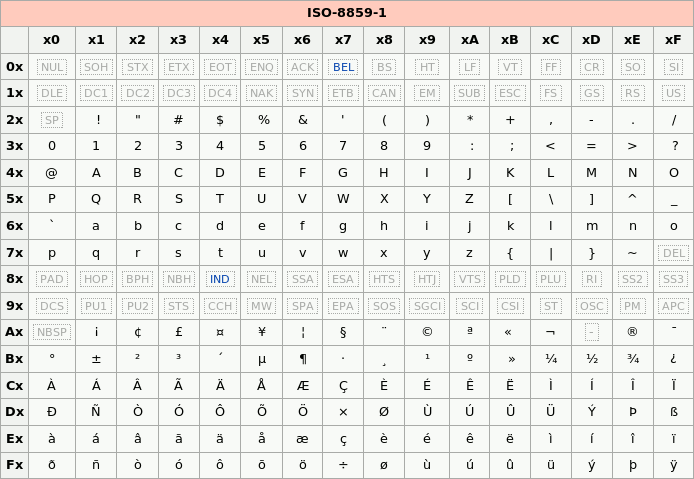
Table ISO-8859-1
256 caractères de la table ISO-8859-1 : figure
Défauts
- insuffisant pour les langues asiatiques
- nécessite de savoir quelle table a été utilisée pour écrire un texte



Unicode
Norme Unicode
Naissance et principe
- 1991 : Unicode 1.0
- attribue un numéro unique à chaque caractère, sans se préoccuper de la manière dont il est codé
- conserve la compatibilité avec ASCII et ISO-8859-1
- largement plus que 256 caractères
Exemples :
Versions
Versions successives pour ajouter des caractères : https://unicode.org/versions/ ou wikipedia
- Unicode 1.0 : 1991
- …
- Unicode 16.0 : 2024
UTF-8
Principe
UTF-8
UTF-8 = Unicode Transformation Format 8 bits
- Unicode est une norme, pas un codage
- UTF-8 est un codage de Unicode
- UTF-8 est un codage variable : 1 à 4 octets par caractère
- utilisation des bits de poids fort pour indiquer le nombre d’octets
UTF-8 : 1 octet
0bbb bbbb
- 1er bit à 0 : caractère ASCII
- 1er bit à 1 : caractère non ASCII, plusieurs octets
UTF-8 : plusieurs octets
Bits de poids fort du 1er octet : indiquent le nombre d’octets utilisés pour encoder le caractère. Les bits restants indiquent la valeur unicode.
110b bbbb 10bb bbbb- 2 octets - 11 bits disponibles - unicodes entre
0x0080et0x07FF - alphabets d’Europe et du Moyen-Orient
- 2 octets - 11 bits disponibles - unicodes entre
1110 bbbb 10bb bbbb 10bb bbbb- 3 octets - 16 bits disponibles - unicodes entre
0x0800et0xFFFF - quasiment tous les caractères
- 3 octets - 16 bits disponibles - unicodes entre
1111 0bbb 10bb bbbb 10bb bbbb 10bb bbbb- 4 octets - 21 bits disponibles - unicodes jusquà 0x1FFFFF
- tous les caractères
- un peu plus compliqué que ça en vrai
Exemple
ord('€')= 8364hex(8364)=0x20ACbin(8364)=0b10 0000 1010 1100: 14 bits- 14 bits => 3 octets
1110 bbbb 10bb bbbb 10bb bbbb0010 00 0010 10 11001110 0010 1000 0010 1010 1100E 2 8 2 A C=E282AC
Exercice
https://fonts.google.com/specimen/Source+Code+Pro/glyphs
ord(':-)')= 128578 (smiley)hex(128578)=0x1F642- …
Écrire le code UTF-8 correspondant.
Adoption
UTF-8 est le codage le plus utilisé dans le monde.
- 2014 : 82% des pages web
- 2017 : 90% des pages web
- 2020 : 95% des pages web
Python 3 : UTF-8 par défaut
Inconvénients
On ne peut pas se déplacer dans une chaîne de caractères en UTF-8 en comptant les octets, il faut partir du début à chaque fois => algorithmes spécifiques.
Python et les chaînes de caractères
Python 3
UTF-8 par défaut
- Python 3 utilise UTF-8 par défaut
ordetchrrenvoient les codes unicodelenrenvoie le nombre de caractères et non le nombre d’octets- Python a aussi des chaînes de caractères binaires (bytes) :
b'...'(pas de caractères, que des octets)- exemple b’\xe2\x82\xac’ pour le symbole euro
- str.encode() et bytes.decode() pour convertir de l’un à l’autre
b'\\xe2\\x82\\xac'.decode('utf-8')=>'€''€'.encode('utf-8')=>b'\\xe2\\x82\\xac''€'.encode('latin1')=> ERREUR'É'.encode('latin1')=b'\\xc9''É'.encode('utf-8')=b'\\xc3\\x89'
Particularités
les chaînes de caractères sont séquentielles : on peut accéder à un caractère par son indice
s = "Hello" print(s[0]) # affiche Hles chaînes de caractères sont immuables : on ne peut pas modifier un caractère directement dans une chaîne
s = "Hello" s[0] = 'h' # ERREURles chaînes de caractères sont itérables : on peut les parcourir avec une boucle
fors = "Hello" for c in s: print(c)
Fonctions de chaînes de caractères
str.upper(): convertit en majusculesstr.lower(): convertit en minuscules'a' in str: teste siaest dansstrstr.capitalize(): met la première lettre en majusculestr.title(): met la première lettre de chaque mot en majusculestr.strip(): supprime les espaces au début et à la finstr.lstrip(): supprime les espaces au débutstr.rstrip(): supprime les espaces à la finstr.replace('a', 'b'): remplace toutes les occurrences deaparbstr.split(): découpe la chaîne en mots (séparateur : espace)str.split('a'): découpe la chaîne en mots (séparateur :a)str.join(liste): concatène les éléments de la liste en les séparant parstrstr.startswith('a'): teste si la chaîne commence parastr.endswith('a'): teste si la chaîne se termine parastr.find('a'): renvoie l’indice de la première occurrence deadans la chaîne, -1 si pas trouvéstr.rfind('a'): renvoie l’indice de la dernière occurrence deadans la chaîne, -1 si pas trouvéstr.count('a'): renvoie le nombre d’occurrences deadans la chaînestr.isalpha(): teste si la chaîne ne contient que des lettresstr.isdigit(): teste si la chaîne ne contient que des chiffresstr.isalnum(): teste si la chaîne ne contient que des lettres et des chiffresstr.islower(): teste si la chaîne ne contient que des lettres minusculesstr.isupper(): teste si la chaîne ne contient que des lettres majusculesstr.isspace(): teste si la chaîne ne contient que des espaces